Büyük Veri (Big Data) ve Hadoop Nedir?

Bu 300’ncü blog yazısı olmasıyla beraber yeni teknolojileride öğrenmek için bir başlangıç olarak görüyorum. Büyük Veri diğer bir deyişle Dev Veri nedir sorusunu cevaplayacak ve Hadoop sisteminin temelini anlayacağız.
1. Büyük Veri Nedir? (Big Data)
Big Data, farklı kaynaklardan elde ettiğimiz düzenli veya düzensiz verileri anlamlı ve işlenebilir hale dönüştürür. Dünyada ki verilerin %90’ının son 3-4 yılda oluştuğu gerçeğiyle hızla büyüyen verinin boyutunu daha rahat anlayabiliriz.
Sosyal medya paylaşımları, blog yazıları, fotoğraf, müzik, video arşivleri, müşteri veya çalışan bilgileri, IoT verileri ve kullanıcı hareketlerini kaydettiğimiz log dosyaları gibi çeşitli kaynaklardan yararlanılır.
Geçmişte bilgi kirliliği olarak görülen bu veriler gereksiz ve faydasız olarak görülmekteydi. İlişkisel veritabanı sistemlerinde (relational database systems) yapılan raporlar sonucunda alınan kararlar, değerlendirilmeye alınamamış. bilgi çöplüğü olarak isimlendirilen veriler nedeniyle eksik veya hatalı kararlar alınmasına sebep olabiliyordu. Büyük Veri kavramıyla bu veriler doğru analiz yöntemleriyle yeni buluşlara ve önemli kararların alınmasında önemli rol oynadı.
Sosyal medyanın hayatımıza girmesiyle beraber veri artışı hızla yükseldi. Petabyte seviyesinde olan bu veriler, exabyte veya zettabyte sevilerine de çıkabilmektedir.
Dev Veri sayesinde işletmeler mevcut müşterilerini elde tutma, yeni müşteriler kazanma, yeni kampanyalar oluşturma, yeni ürün veya hizmet fikirleri oluşturmada kolaylık sağlar. Kısacası Dev Veri ile görülemeyen veya düşünelemeyen bir çok olgu karşımıza çıkabilir ve daha doğru karar alınmasını sağlayabilir.
1.1 Büyük Verinin Sınıflandırılması

1.2. Büyük Veri Bileşenleri
Big Data (Dev Veri) nin oluşumunda 5 bileşen vardır. Bu bileşenler 5V olarak adlandırılmaktadır.
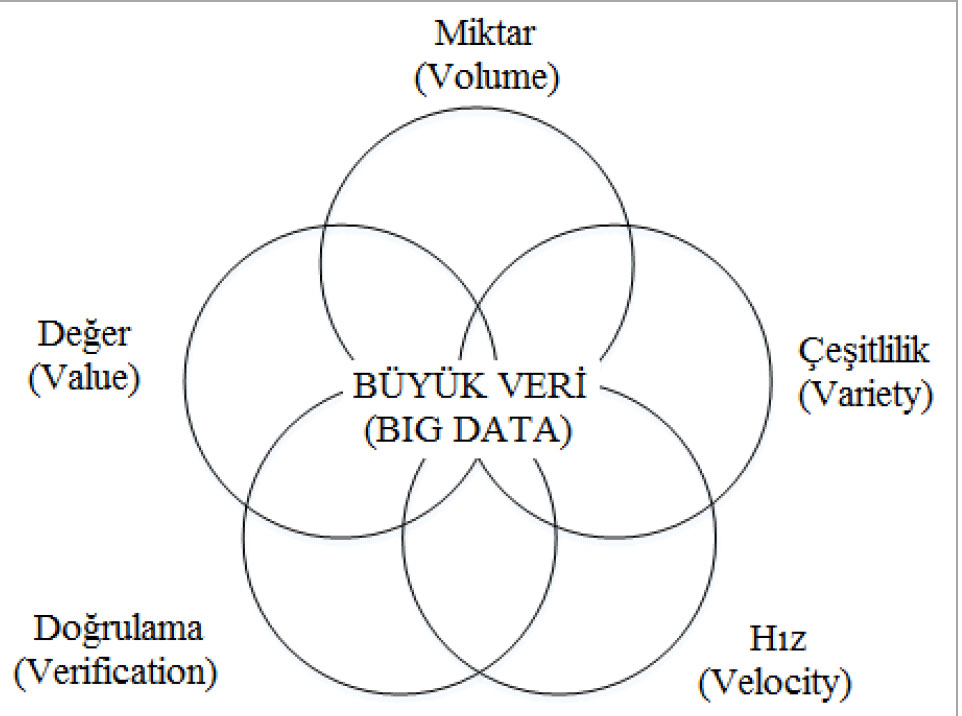
Variety (Çeşitlilik): Çeşitli kaynaklardan elde edilmiş düzenli veya düzensiz veri, analiz edilmesindeki anlamı artırdığından önemli bir bileşendir.
Velocity (Hız): Büyük veri hızla büyüyen ve hızla işlenen olması gerekmektedir.
Volume (Veri Büyüklüğü): Hızla büyüyen dev veri ile nasıl başa çıkacağımızı iyi düşünmemiz ve planlarımızı bu doğrultuda yapmamız gerekmektedir.
Verification (Doğrulama): Gereksiz ve değişime uğramış büyük verileri analiz etmek ciddi vakit kaybına ve hatalı sonuçlara yol açabilir. Bu sebeple verinin doğruluğu(Vertification) kriterler içinde en hassas olanların biridir.
Value (Değer): Belkide en önemli katmanlardan bir tanesi de “Değer” katmanıdır, verilerimiz yukarıdaki veri bileşenlerinden filtrelendikten sonra büyük verinin üretimi ve işlenmesi katmanlarında elde edilen verilerin şirketimiz için artı değer sağlıyor olması gerekiyor.
Big Data Kullanım Alanları İle İlgili Örnekler:
Firmaların müşterileri, malzeme tedarikçileri, şirket içerisindeki her türlü işlem ve ürünleri ile ilgili trilyonlarca bayt’ lık veri toplamakta ve anlamlı raporlar üretilmekte.
Sosyal medya paylaşımları sayesinde hergün milyarlarca kilobayt veri elde edilmekte.
Günümüzde normal bir tüketicinin günlük yaşamında internette yaptığı haberleşme, arama, satın alma ve paylaşma türü işlemlerin yarattığı verilerin de tümü saklanmakta.
Sağlık Kuruluşları; hastalarına yönelik bireysel ve kişiselleştirilmiş sağlık hizmetleri sağlayabilmek için, bireysel durumdaki verileri kendi sayısal ortamlarında depolamaktalar.
Bankalar, müşterileri ile ilgili sakladıkları bilgiler aracılığı ile kullanıcılarını tanıyan ve internet şubesinde o gün için hangi hizmeti aldığını bilen aynı zamanda anasayfayı, menüleri en etkin hale getiren(kişiselleştirme uygulamaları), müşterilerine hatırlatmalar yapan, kişiselleştirilmiş arayüz deneyimi, zengin içerik ve sürekli hizmet sağlayan şube haline geldi.
Arama motorları sayesinde milyonlarca sayfa arasında en doğru ve en hızlı veriye ulaşabilmemiz için yine aynı şekilde arka tarafdaki büyük veriler ve bunların anlamlı hale getirilmeleri yatmaktadır.
Big Data (Büyük Veri) ile hayal gücünüzü eş değer tutabilirsiniz çünkü bu kadar büyük veri kümeleri ile yapabileceğin herşey hayal gücünüz ile sınırlıdır sadece ne yapmak ve neyi bilmek istediğimizi iyi anlamamız gerekmektedir.
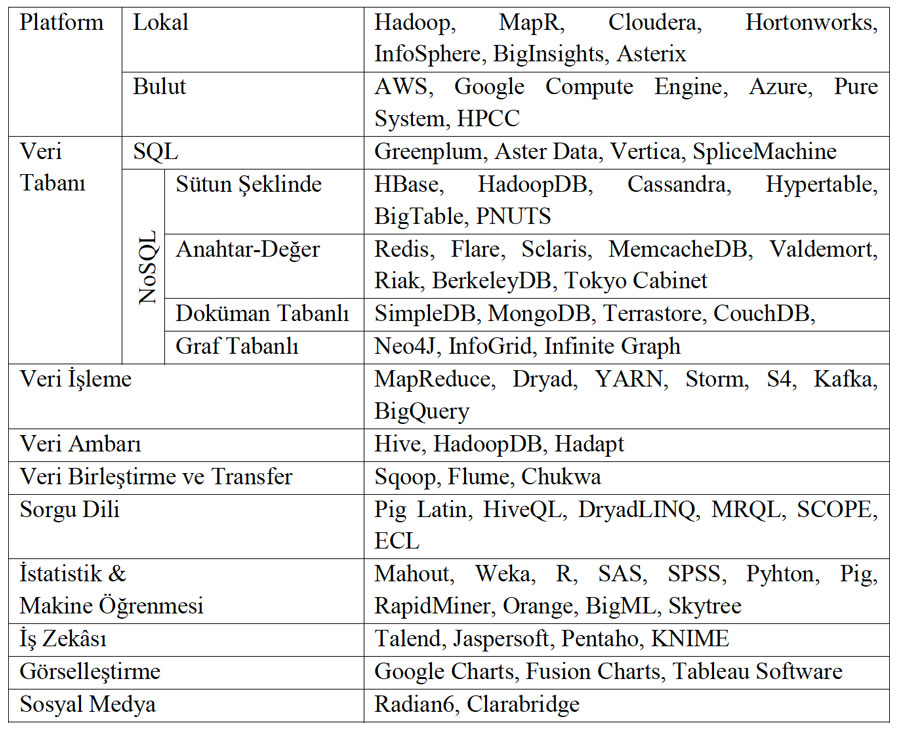
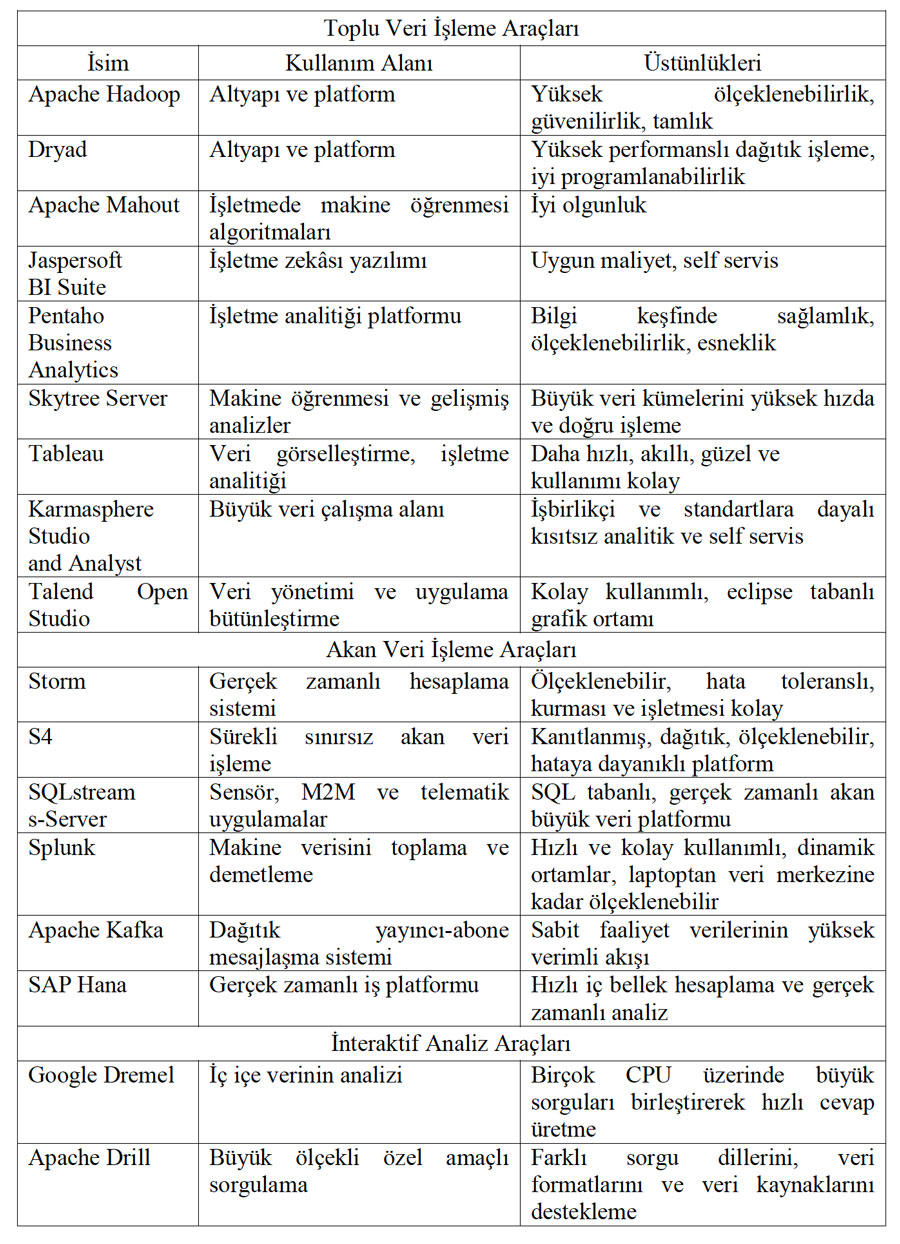
1.3. Büyük Veri Araçları
2. Hadoop Nedir?
Apache Hadoop, açık kaynak kodlu olarak Java için geliştirilmiş büyük veri kümeleri işleme aracıdır. Depolama bölümü olarak dağıtık veri sistemi olarak bilinen HDFS ve işleme modülü olarak MapReduce kullanılmaktadır. Hadoop’da datayı sisteme yüklediğimizde varsayılan olarak 64MB’lık bloklara ayırarak yazar. Bu datalar birden fazla ve farklı sunucular üzeirnde 3 kopya olarak dağıtılarak yedeklenir.
2.1. Hadoop Projesi’nin 4 Bileşeni
Hadoop Common: Büyük veri işlemesinde yardımcı olan ve tüm Hadoop modüllerini destekleyen ortak modüller.
Hadoop Distributed File System (HDFS): Büyük miktardaki veriye yüksek iş/zaman oranı (throughput) ile erişim sağlayan Dağıtık Dosya Yönetim Sistemidir. Birçok makinedeki dosya sistemlerini birbiriyle bağlayarak tek bir dosya sistemi gibi gözükmesini sağlar. HDFS, düğüm noktalarının (node’ların) her zaman yüzde 100 çalışamayacağını, kesintiler olabileceğini baştan kabul eder. Bu yüzden veri güvenliğini, verinin birden fazla düğüm noktasına kopyalayarak sağlar.
Hadoop YARN: İş zamanlayıcı (job scheduler) ve kaynak yönetimini yapan bir dizi kütüphane.
Hadoop MapReduce: YARN temelli, büyük miktarda veriyi paralel olarak işlemeye yarayan bir sistem. Gelen iş yükünü tanıyarak, arka plandaki bilgisayar düğüm noktalarına bu iş yükünü tahsis eden imkanlar sunar.
Popüler Hadoop temelli projeler;
Cassandra: Ölçeklenebilir, çok-node’lu, kümelenmiş veritabanı.
Chukwa: Dağıtık ve Büyük Sistemleri yönetmek için veri toplama sistemi.
Hive: Veri Özetleme ve “ad hoc” sorgu yazma ortamı sağlayan bir veri ambarı mimarisi.
Pig: Paralel İşlem Tasarımı yapmak için hazırlanmış, veri akışlarını ve çalıştırma planlaması yapılabilecek bir dil.
2.2. Hadoop Verileri Nasıl Saklar?
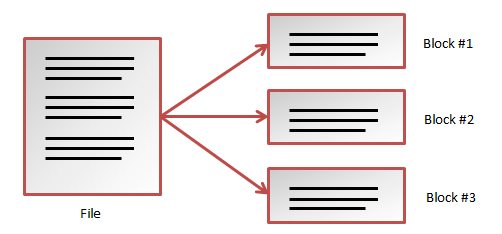
HDFS bileşeni verileri saklamayı sağlar. Verileri farklı bloklara ayırarak, Hadoop Cluster üzerinde farklı node lara dağılır.
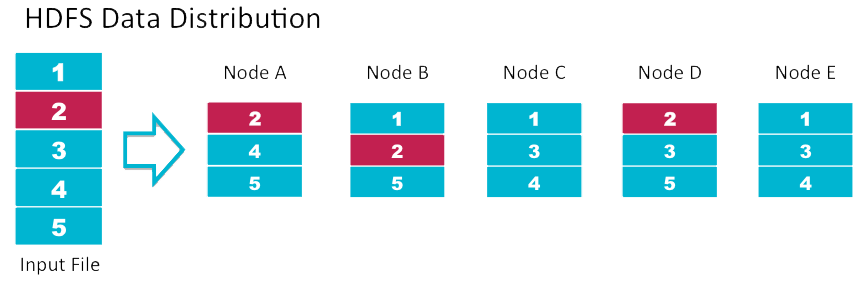
Örneğin yukarıda ki input file içerisnde ki bloklar farklı node lara dağıtılmıştır. Her blok 3 farklı node üzerinde dağıtılmıştır. Olası bir durumuda node lardan biri zarar gördüğünde veya istenemyen başka bir durum gerçekleştiğinde veri kaybının yaşanmasını engellemektir.
2.3. Hadoop Verileri Nasıl İşler?
Büyük verileri işlemimizi sağlayan MapReduce bileşenidir. Veriler yüklendikten sonra Map ve Reduce fazları gerçekleştirilir.
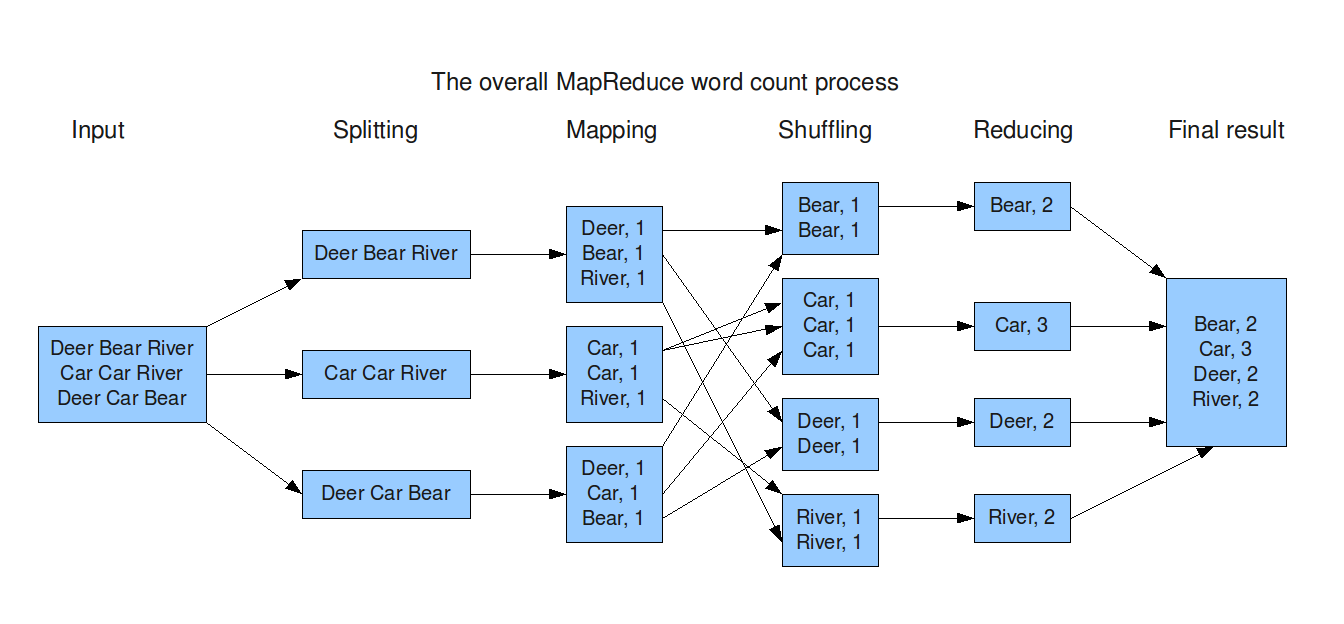
Yukarıda ki MapReduce adımında bşr text dosyasının içersinde ki kelime sayısını bulma işlemi adım adım aşağıda ki gibi gerçekleşir.
Spliting: Veriler varsayılan olarak 64 MB lık bloklara ayrılır . Bu değer değiştirilebilir.
Mapping: Burada her bir kelime key(word) ve value(1) şeklinde bölümlere ayrılır.
Shuffling: Map işleminden çıkan sonuçları Reducer a yönlendirir. Amacımız word-count uygulaması oldugu için aynı kelime grubu aynı Reducer a yönlendirilir.
Reducing: Gelen sonuçlar üzerinden toplama işlemi yapılır ve sonuçlar istediğiniz kaynaklara yazılır (HDFS , SQL , NoSQL).
2.4. Diğer Araçlar
3. Kaynaklar
https://circlelove.co/buyuk-veri-bigdata
http://veriakademi.com/hadoop-nedir
http://www.bthaber.com/yazarlar/%E2%80%9Cnedir-bu-hadoop%E2%80%9D/1/7272




